




标题:实时数据高效写入Hudi:架构与实践解析
随着大数据时代的到来,实时数据处理成为了企业数据分析的关键环节。Hudi(Hadoop Upsert Distributed Dataset)作为一种新型分布式数据存储系统,因其高效、可靠的写入能力,在实时数据处理领域得到了广泛应用。本文将深入探讨实时数据写入Hudi的架构与实践,帮助读者了解如何利用Hudi实现高效的数据写入。
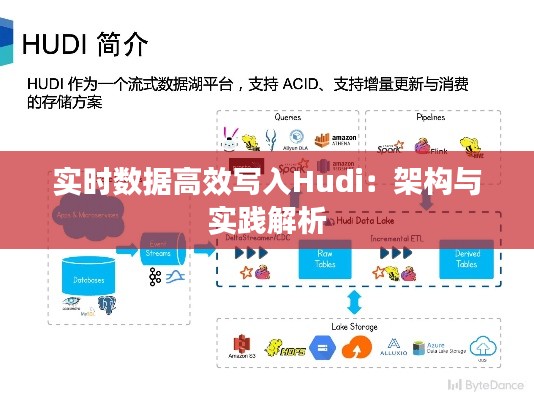
一、Hudi简介
Hudi是一款由Cloudera开源的分布式数据存储系统,它基于Hadoop生态,旨在提供高效、可靠的实时数据写入能力。Hudi支持多种数据源,如HDFS、Amazon S3等,并支持多种数据格式,如Parquet、ORC等。其主要特点如下:
-
高效写入:Hudi采用了一种称为“Write-Ahead Log”的机制,将数据变更记录在日志中,从而实现高效的写入操作。
-
支持多种数据操作:Hudi支持数据的插入、更新、删除等操作,且支持事务性操作,保证了数据的一致性。
-
高可用性:Hudi支持数据的多副本存储,确保了数据的高可用性。
-
支持实时查询:Hudi支持实时查询,可以满足实时数据处理的业务需求。
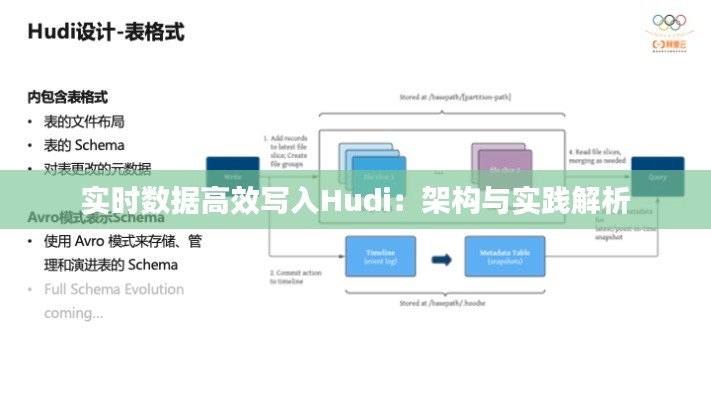
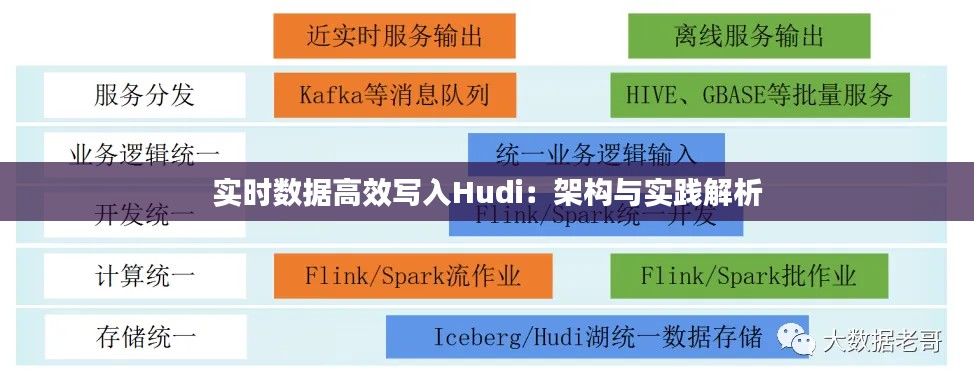
二、实时数据写入Hudi的架构
实时数据写入Hudi的架构主要包括以下组件:
-
数据源:数据源可以是各种实时数据源,如Kafka、Flume等。
-
数据处理引擎:数据处理引擎负责对实时数据进行处理,如过滤、转换等。
-
Hudi客户端:Hudi客户端负责将处理后的数据写入Hudi。
-
Hudi服务:Hudi服务负责管理Hudi集群,如数据分区、副本管理等。
-
HDFS/Amazon S3:HDFS或Amazon S3作为Hudi的数据存储介质。
以下是实时数据写入Hudi的架构图:
数据源 --> 数据处理引擎 --> Hudi客户端 --> Hudi服务 --> HDFS/Amazon S3三、实时数据写入Hudi的实践
- 数据源配置
首先,需要配置数据源,如Kafka。以下是一个简单的Kafka配置示例:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");- 数据处理引擎
数据处理引擎负责对实时数据进行处理,如过滤、转换等。以下是一个简单的数据处理引擎示例:
public class DataProcessor {
public static void main(String[] args) {
// 读取Kafka数据
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("input_topic"));
// 处理数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (Record<String, String> record : records) {
// 处理数据
System.out.println("Received: " + record.value());
}
}
}
}- Hudi客户端
Hudi客户端负责将处理后的数据写入Hudi。以下是一个简单的Hudi客户端示例:
public class HudiClient {
public static void main(String[] args) {
// 配置Hudi客户端
Configuration config = new Configuration();
config.set("hoodie.datasource.write.recordkey.field", "id");
config.set("hoodie.datasource.write.partitionpath.field", "partition");
config.set("hoodie.datasource.write.precombine.field", "timestamp");
// 创建Hudi客户端
HoodieWriteClient writeClient = HoodieWriteClient.newBuilder()
.setConf(config)
.build();
// 写入数据
List<WriteOperation> writeOperations = new ArrayList<>();
writeOperations.add(WriteOperation.insert(new HoodieRecord("id", "partition", "timestamp", "data")));
writeClient.writeAll(writeOperations);
// 关闭Hudi客户端
writeClient.close();
}
}- Hudi服务
Hudi服务负责管理Hudi集群,如数据分区、副本管理等。在实际应用中,可以根据需求选择合适的Hudi服务,如Hudi on Spark、Hudi on Flink等。
四、总结
本文介绍了实时数据写入Hudi的架构与实践,通过配置数据源、数据处理引擎、Hudi客户端和Hudi服务,可以实现高效、可靠的实时数据写入。Hudi凭借其优异的性能和灵活性,在实时数据处理领域具有广泛的应用前景。
转载请注明来自中国大学生门户网站,本文标题:《实时数据高效写入Hudi:架构与实践解析》





 陇ICP备16000129号-1
陇ICP备16000129号-1