




标题:《离线数据仓库向实时数仓转型:ETL开发策略解析》
随着大数据时代的到来,企业对数据的需求日益增长,传统的离线数据仓库已经无法满足实时性要求。为了更好地应对这一挑战,实时数仓应运而生。本文将探讨离线数据仓库向实时数仓转型的过程,重点分析ETL(Extract, Transform, Load)开发策略,以帮助企业实现数据的高效处理和分析。
一、离线数据仓库与实时数仓的区别
- 数据实时性
离线数据仓库的数据更新周期较长,通常为每天或每周,而实时数仓的数据更新周期较短,甚至可以达到秒级。
- 数据处理能力
离线数据仓库的处理能力相对较弱,难以应对大规模、高并发的数据处理需求。实时数仓则具备较强的数据处理能力,能够满足实时性要求。
- 数据存储方式
离线数据仓库通常采用关系型数据库存储数据,而实时数仓则采用NoSQL数据库、分布式文件系统等存储方式。
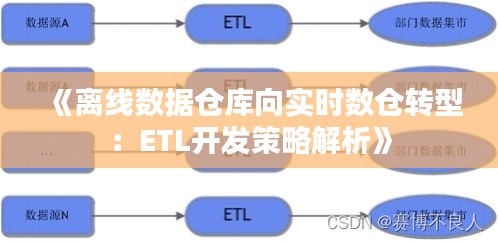
二、离线数据仓库向实时数仓转型的过程
- 数据采集
实时数仓的数据采集环节需要关注数据的实时性,可采用以下几种方式:
(1)日志采集:通过日志收集工具,实时采集业务系统产生的日志数据。
(2)API接口:通过调用业务系统的API接口,实时获取数据。
(3)消息队列:利用消息队列技术,实现数据的实时传输。
- 数据存储
实时数仓的数据存储环节需要考虑数据的实时性和扩展性,以下是一些常用的存储方式:
(1)NoSQL数据库:如MongoDB、Cassandra等,具备高并发、可扩展的特点。
(2)分布式文件系统:如Hadoop HDFS,适用于大规模数据存储。
(3)内存数据库:如Redis,适用于对实时性要求较高的场景。
- 数据处理
实时数仓的数据处理环节需要关注数据的实时性和准确性,以下是一些常用的数据处理技术:
(1)流处理技术:如Apache Kafka、Apache Flink等,能够实现数据的实时处理。
(2)批处理技术:如Apache Spark、Hadoop MapReduce等,适用于大规模数据处理。
(3)实时计算引擎:如Apache Storm,适用于对实时性要求较高的场景。
- 数据加载
实时数仓的数据加载环节需要关注数据的实时性和一致性,以下是一些常用的数据加载方式:
(1)增量加载:仅加载自上次加载以来发生变化的数据。
(2)全量加载:加载全部数据。
(3)实时加载:实时加载最新数据。
三、ETL开发策略解析
- 数据抽取
数据抽取是ETL过程中的第一步,需要关注以下问题:
(1)数据源:确定数据源,包括日志、API接口、消息队列等。
(2)数据格式:了解数据源的数据格式,如JSON、XML、CSV等。
(3)数据质量:确保数据抽取过程中数据质量不受影响。
- 数据转换
数据转换是ETL过程中的核心环节,需要关注以下问题:
(1)数据清洗:去除无效、错误的数据。
(2)数据整合:将来自不同数据源的数据进行整合。
(3)数据转换:根据业务需求,对数据进行格式转换、计算等操作。
- 数据加载
数据加载是ETL过程中的最后一步,需要关注以下问题:
(1)目标数据库:确定目标数据库,如NoSQL数据库、分布式文件系统等。
(2)数据加载策略:选择合适的加载策略,如增量加载、全量加载等。
(3)数据一致性:确保数据加载过程中数据的一致性。
总结
离线数据仓库向实时数仓转型是大数据时代企业应对数据挑战的必然趋势。本文从数据采集、存储、处理和加载等方面,探讨了离线数据仓库向实时数仓转型的过程,并重点分析了ETL开发策略。通过合理运用ETL技术,企业可以实现数据的高效处理和分析,为业务决策提供有力支持。
转载请注明来自中国大学生门户网站,本文标题:《《离线数据仓库向实时数仓转型:ETL开发策略解析》》






 陇ICP备16000129号-1
陇ICP备16000129号-1