




标题:实时数据获取:表格动态抓取网站信息新篇章
随着互联网技术的飞速发展,数据已经成为企业决策、产品研发、市场分析等领域不可或缺的重要资源。如何高效、实时地获取网站数据,成为众多企业和开发者的关注焦点。本文将详细介绍表格实时获取网站数据的方法,帮助大家掌握这一技能,为工作带来便利。
一、引言
表格作为数据展示的重要方式,在各个领域都得到了广泛应用。然而,传统的数据获取方式往往需要手动采集、整理,效率低下且容易出错。为了解决这一问题,本文将介绍一种表格实时获取网站数据的方法,通过编程实现数据的自动抓取,提高工作效率。
二、表格实时获取网站数据的方法
- 网络爬虫技术
网络爬虫(Web Crawler)是一种自动抓取网站信息的程序,可以按照一定的规则遍历互联网,获取所需数据。以下是使用网络爬虫技术实现表格实时获取网站数据的基本步骤:
(1)选择合适的爬虫框架:目前市面上有许多优秀的爬虫框架,如Scrapy、BeautifulSoup等。根据实际需求选择合适的框架。
(2)分析目标网站结构:了解目标网站的结构,包括页面布局、数据存储方式等,为编写爬虫程序提供依据。
(3)编写爬虫程序:根据目标网站结构,编写爬虫程序,实现数据的抓取。在编写过程中,注意遵守目标网站的robots.txt协议,尊重网站版权。
(4)数据存储:将抓取到的数据存储到数据库或文件中,方便后续处理和分析。
- API接口调用
许多网站提供API接口,允许开发者通过编程方式获取数据。以下是使用API接口实现表格实时获取网站数据的基本步骤:
(1)了解API接口:查阅目标网站的API文档,了解接口的调用方式、参数、返回数据格式等。
(2)编写API调用代码:根据API文档,编写调用接口的代码,实现数据的获取。
(3)数据存储:将获取到的数据存储到数据库或文件中,方便后续处理和分析。
- 数据库连接
对于一些需要频繁访问的数据,可以考虑使用数据库连接实现表格实时获取网站数据。以下是使用数据库连接实现数据获取的基本步骤:
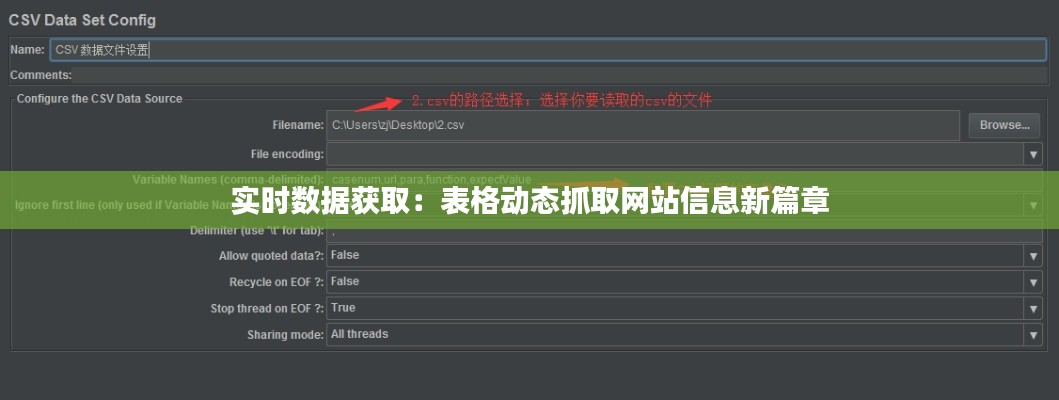
(1)选择合适的数据库:根据实际需求选择合适的数据库,如MySQL、Oracle等。
(2)建立数据库连接:编写代码建立数据库连接,获取数据库操作权限。
(3)编写SQL查询语句:根据需求编写SQL查询语句,获取所需数据。
(4)数据存储:将查询到的数据存储到数据库或文件中,方便后续处理和分析。
三、总结
表格实时获取网站数据的方法有很多,本文介绍了网络爬虫技术、API接口调用和数据库连接三种方法。通过掌握这些方法,我们可以轻松实现数据的自动抓取,提高工作效率。在实际应用中,可以根据具体需求选择合适的方法,实现数据的实时获取。
转载请注明来自中国大学生门户网站,本文标题:《实时数据获取:表格动态抓取网站信息新篇章》






 陇ICP备16000129号-1
陇ICP备16000129号-1