




标题:《Spark实时增量同步:高效数据流处理解决方案详解》
随着大数据时代的到来,实时数据处理成为企业业务决策的重要支撑。Spark作为一款高性能的大数据处理框架,在实时增量同步方面具有显著优势。本文将详细介绍Spark实时增量同步的原理、实现方法以及在实际应用中的优势。
一、Spark实时增量同步的原理
- 数据流处理
Spark实时增量同步是基于数据流处理技术实现的。数据流处理是指对实时数据流进行实时分析、处理和挖掘的技术。在Spark中,数据流处理主要依赖于Spark Streaming模块。
- 增量同步
增量同步是指将源数据集中最新的数据同步到目标数据集中。在Spark实时增量同步中,主要采用以下两种方式实现:
(1)基于时间窗口:通过设置时间窗口,将源数据集中的数据按照时间顺序进行分组,然后将每个时间窗口内的数据同步到目标数据集中。
(2)基于水印:水印是一种特殊的标记,用于标识数据流的起始位置。通过计算水印,可以确定哪些数据已经同步,哪些数据需要同步。
二、Spark实时增量同步的实现方法
- Spark Streaming
Spark Streaming是Spark框架中用于实时数据处理的核心模块。它支持多种数据源,如Kafka、Flume、Twitter等。以下是使用Spark Streaming实现实时增量同步的步骤:
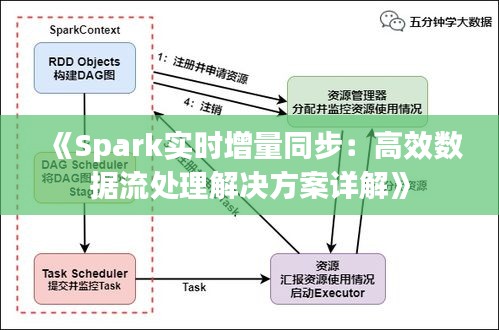
(1)创建Spark Streaming上下文:使用SparkSession.builder().appName("SparkStreamingExample")创建Spark Streaming上下文。
(2)定义数据源:根据实际需求,选择合适的数据源,如Kafka、Flume等。
(3)定义处理逻辑:根据业务需求,编写数据处理逻辑,如数据清洗、转换、聚合等。
(4)启动Spark Streaming:使用streamingContext.start()启动Spark Streaming。
(5)等待Spark Streaming处理完成:使用streamingContext.awaitTermination()等待Spark Streaming处理完成。
- Spark SQL
Spark SQL是Spark框架中用于处理结构化数据的模块。在实时增量同步中,可以使用Spark SQL对数据进行查询、转换和同步。以下是使用Spark SQL实现实时增量同步的步骤:
(1)创建SparkSession:使用SparkSession.builder().appName("SparkSQLExample")创建SparkSession。
(2)读取数据源:使用Spark SQL读取源数据集。
(3)定义处理逻辑:根据业务需求,编写数据处理逻辑,如数据清洗、转换、聚合等。

(4)将处理后的数据写入目标数据集:使用Spark SQL将处理后的数据写入目标数据集。
三、Spark实时增量同步的优势
-
高性能:Spark采用内存计算和分布式处理,具有高性能的特点,能够快速处理大量数据。
-
易于扩展:Spark支持水平扩展,可以根据需求增加节点数量,提高数据处理能力。
-
丰富的API:Spark提供丰富的API,包括Spark SQL、Spark Streaming等,方便用户进行数据处理。
-
兼容性强:Spark支持多种数据源,如HDFS、HBase、Kafka等,方便用户进行数据集成。
-
实时性强:Spark Streaming支持实时数据处理,能够满足企业对实时数据的需求。
总之,Spark实时增量同步是一种高效的数据流处理解决方案,具有诸多优势。在实际应用中,企业可以根据自身需求选择合适的实现方法,以提高数据处理效率。
转载请注明来自中国大学生门户网站,本文标题:《《Spark实时增量同步:高效数据流处理解决方案详解》》






 陇ICP备16000129号-1
陇ICP备16000129号-1