

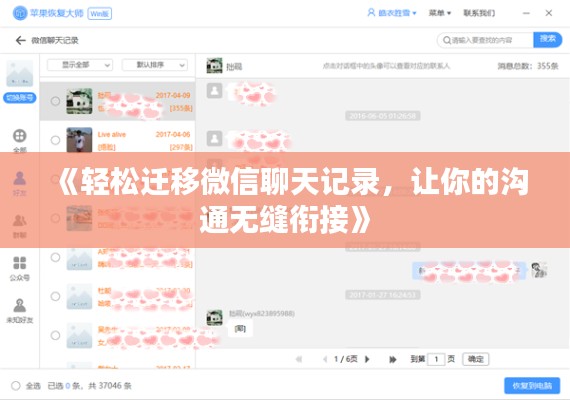



标题:《实时爬取个人微博:技术解析与保存方法详解》
随着互联网的快速发展,微博已成为人们获取信息、分享生活的重要平台。实时爬取个人微博并保存,对于研究社交媒体、分析用户行为具有重要意义。本文将详细介绍实时爬取个人微博的技术原理、实现方法以及保存技巧。
一、实时爬取个人微博的原理
实时爬取个人微博,即通过编写程序,实时获取用户在微博上的动态。其原理如下:
-
利用微博API获取数据:微博开放平台提供了丰富的API接口,开发者可以通过API获取用户在微博上的动态,如微博正文、评论、转发等。
-
模拟登录:为了获取个人微博数据,需要模拟登录微博账号。通过Python等编程语言,可以调用微博API进行登录,获取登录凭证。
-
定时任务:设置定时任务,定期调用微博API,获取个人微博动态。
-
数据存储:将获取到的微博数据保存至数据库或文件中,以便后续分析。

二、实时爬取个人微博的实现方法
以下以Python为例,介绍实时爬取个人微博的实现方法:
- 安装所需库
首先,需要安装以下Python库:requests、BeautifulSoup、pandas、lxml等。
- 获取微博API接口
登录微博开放平台,申请开发者资质,获取API接口。
- 编写爬虫代码
(1)模拟登录:使用requests库,模拟登录微博账号,获取登录凭证。
(2)获取个人微博动态:使用requests库,调用微博API接口,获取个人微博动态。

(3)解析数据:使用BeautifulSoup库,解析微博动态数据。
(4)数据存储:使用pandas库,将解析后的数据保存至数据库或文件。
- 设置定时任务
使用Python的schedule库,设置定时任务,定期执行爬虫代码。
三、数据保存技巧
-
数据库存储:将微博数据保存至数据库,如MySQL、MongoDB等。数据库存储具有查询速度快、数据安全性高等优点。
-
文件存储:将微博数据保存至文件,如CSV、JSON等。文件存储简单易用,但查询速度较慢。
-
数据清洗:在数据保存前,对数据进行清洗,去除无用信息,提高数据质量。
四、总结
实时爬取个人微博并保存,对于研究社交媒体、分析用户行为具有重要意义。本文从原理、实现方法以及保存技巧等方面,详细介绍了实时爬取个人微博的过程。通过本文的学习,读者可以掌握实时爬取个人微博的技术,为后续研究提供数据支持。
转载请注明来自中国大学生门户网站,本文标题:《《实时爬取个人微博:技术解析与保存方法详解》》






 陇ICP备16000129号-1
陇ICP备16000129号-1